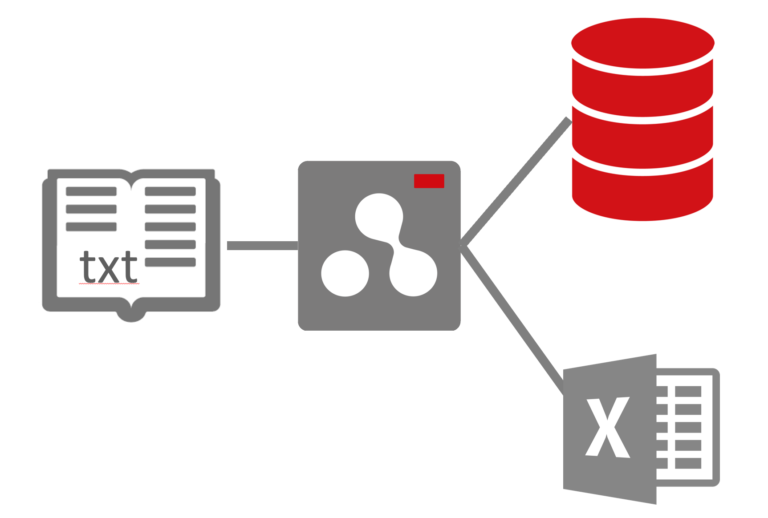
The architecture we created to understand, read and extract informacion from documents. All our current solutions are based on this architecture.
Combined with a complete services layer, it can get document from APIs, FTP folders, remote locations, or just receive them through a Cloud API, and it can store the results in a database, an spreadsheet, a remote API call,…
On top of it we created a complete toolset to create new solutions in a fast, reliable way, and most importantly, without the need to code anymore. Atomian Highlight allows us to fully explain and govern how our technology understands and extracts information from documents of any kind
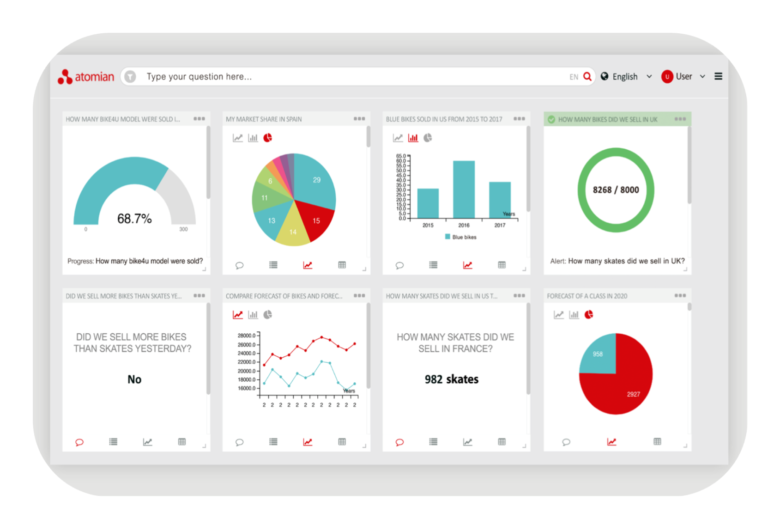
One of Atomian’s habilities is to understand natural language queries, and retrieve the relevant, deterministic answer to those queries. It can generate charts, tables, or plain straight answers from data collected through different sources, including Atomian Highlight processes.
You can see how it works in our YouTube Channel. This screen capture on the right is an actual dashboard built with Atomian Discover. It took exactly 90 seconds to build it from a blank page.

This is a ongoing project.
Atomian is entirely based on a universal knowledge model, the Atomian Model. It allows us to represent any kind of knowledge, with no restrictions. The Atomian model is symbolic and atomistic, it has indivisible pieces of symbolic knowledge.
So it makes sense building a universal inference engine on top of it, that will be capable of creating new atoms of knowledge from the existing ones. The commercial application of this inference engine will will a universal analytics engine, without the need to train costly models.
Contact us for more information about Atomian Analytics.